How to get the 3rd or 4th, so on highest earning employee name from a DB table.
One interesting question asked in many interviews like -
How to get the 3rd or 4th, so on highest earning employee name from a DB table.
Below I will be taking Oracle11g to get this answer & if you are using your personal setup then you will be having default table – emp
Output of – select * from emp
How to get the 3rd or 4th, so on highest earning employee name from a DB table.
Below I will be taking Oracle11g to get this answer & if you are using your personal setup then you will be having default table – emp
Output of – select * from emp
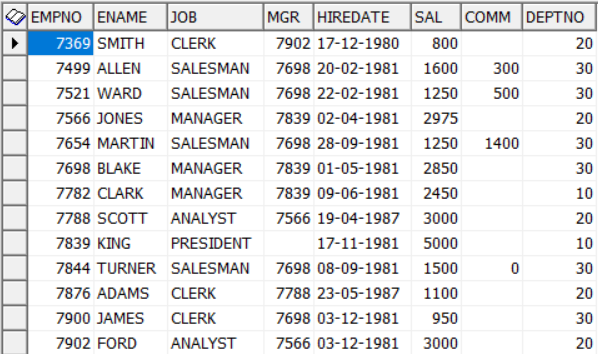
From this we want to get, suppose, 3rd highest earning employee name.
We can use sorting to get the ordered list of employees on the basis of salary like –
select * from emp order by sal desc;
We can use sorting to get the ordered list of employees on the basis of salary like –
select * from emp order by sal desc;
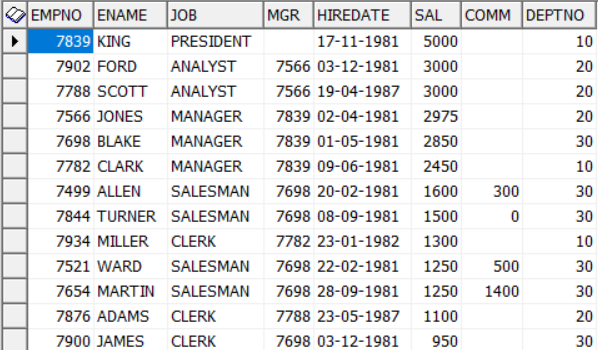
Now see the above results, here one can ask the question to clarify if we need to give same rank to the employees with equal salary or must be different. Like as shown above, should I need to give name of Scott or Jones as the answer for 3rd highest earning employee.
So depending on the requirement & expected result, we can take the approach like shown below –
Case 1 : If we are expecting ‘Scott’ as the result, i.e., Scott will be considered 3rd highest earning employee.
But how Scott comes 3rd everytime? Reason of this, I am still trying to find & understand. If you know then please share.
But if any other parameter to order the employees as per their salary then we can include to get the correct answers. For now I am not taking any other parameter here, just taking salary.
So below query will give the result as ‘Scott’ as per the data shown above –
select * from (select rownum r, empno, ename, sal from (select empno, ename, sal from emp order by sal desc)) where r = 3;
Just change the value of r above to get the required result.
OR
If 2 or more employees are at the same salary then you would like to rank the employees as per ttheir names & then get the required employee name, then try below way also -
select rownum, ename from (
select * from emp order by sal desc, ename asc) group by rownum, ename having rownum = 5;
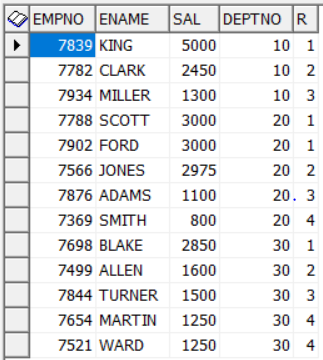
Case 2 : If the requirement is to consider same values at the same rank, then ‘Jones’ is the expected answer as per the data shown above. Here dense_rank() comes to rescue, though we have rank() too but this rank() will not give rank 3 to any record, Jones will get rank as 4 & Ford & Scott both will get rank as 2. So to put the proper ranking, we will dense_rank() here as shown below –
select * from (select ename, sal, dense_rank() over(order by sal desc) r from emp) where r = 3;
You can get the ranking in every department also like shown below –
select * from (select empno, ename, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp);
Note – partition by, it does that work for you to get below result
So depending on the requirement & expected result, we can take the approach like shown below –
Case 1 : If we are expecting ‘Scott’ as the result, i.e., Scott will be considered 3rd highest earning employee.
But how Scott comes 3rd everytime? Reason of this, I am still trying to find & understand. If you know then please share.
But if any other parameter to order the employees as per their salary then we can include to get the correct answers. For now I am not taking any other parameter here, just taking salary.
So below query will give the result as ‘Scott’ as per the data shown above –
select * from (select rownum r, empno, ename, sal from (select empno, ename, sal from emp order by sal desc)) where r = 3;
Just change the value of r above to get the required result.
OR
If 2 or more employees are at the same salary then you would like to rank the employees as per ttheir names & then get the required employee name, then try below way also -
select rownum, ename from (
select * from emp order by sal desc, ename asc) group by rownum, ename having rownum = 5;
Case 2 : If the requirement is to consider same values at the same rank, then ‘Jones’ is the expected answer as per the data shown above. Here dense_rank() comes to rescue, though we have rank() too but this rank() will not give rank 3 to any record, Jones will get rank as 4 & Ford & Scott both will get rank as 2. So to put the proper ranking, we will dense_rank() here as shown below –
select * from (select ename, sal, dense_rank() over(order by sal desc) r from emp) where r = 3;
You can get the ranking in every department also like shown below –
select * from (select empno, ename, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp);
Note – partition by, it does that work for you to get below result
===============================================================================================
Question : You have one employee table like shown above. Now requirement is to add 1000 to every employee's salary.
This question was asked to me in telephonic interview for Sarathi Softech.
Solution : 3 Solutions can be possible for such requirements but depends on the exact requirement & your interviewer
knows about.
One is you can create PL/SQL block, like some procedure or function & in that create & open a cursor on this
table. Loop through each row using cursor, fetch each salary & update that salary by adding 1000. So this way you
will be updating each row & this way will specifically useful if you have to do some other processing also while
doing this.
Second, if you just need to add some particular amount to each employee's salary which is present in the table,
then you can use below simple update statement.
update emp set sal = sal + 1000;
Third, if you want to add some amount to the employee's salary when either the employee record is inserted or
updated in the table then you can create one trigger on after insert and update.
So in above question direct answer is 'Second', though it didn't strike to me that time. But again you have to select
any solution once you have understood requirements properly & can understand all the possible scenarios.
Question : You have one employee table like shown above. Now requirement is to add 1000 to every employee's salary.
This question was asked to me in telephonic interview for Sarathi Softech.
Solution : 3 Solutions can be possible for such requirements but depends on the exact requirement & your interviewer
knows about.
One is you can create PL/SQL block, like some procedure or function & in that create & open a cursor on this
table. Loop through each row using cursor, fetch each salary & update that salary by adding 1000. So this way you
will be updating each row & this way will specifically useful if you have to do some other processing also while
doing this.
Second, if you just need to add some particular amount to each employee's salary which is present in the table,
then you can use below simple update statement.
update emp set sal = sal + 1000;
Third, if you want to add some amount to the employee's salary when either the employee record is inserted or
updated in the table then you can create one trigger on after insert and update.
So in above question direct answer is 'Second', though it didn't strike to me that time. But again you have to select
any solution once you have understood requirements properly & can understand all the possible scenarios.
===============================================================================================
Question : One another interesting Question can be asked by the interviewer is -
a) Find the number of duplicate records.
OR
b) Find the number of records which have duplicates in the given table.
OR
c) Remove all the duplicate records such that all records are unique in the given table.
OR
d) Remove the duplicates of a particular record in the table.
Ans : If you see all these questions are the variations of the same kind of problem. So if you get the crux of the problem here,
you can solve all such problems in different ways including RANK(). Using RANK(), you have to check on internet, I am
giving other way here. I assure you 50% interviewers ask these questions after getting their answers from Internet.
For (a) First get the clarity about the criteria on the basis of which you will consider 2 records as same. Till you get this
clarity, you can't write a correct solution ever. Here I am considering the 'Employee Name' as deciding factor for all the
questions. So now we need to find the difference between total number of records in the given table & the count of
distinct records in that table like -
select count(*)-count(distinct ename) as "Number of duplicate records" from emp
For (b) we don't need to find the number of duplicate records, but we need to find the number of those records which
have duplicates, got the trick here? So first we need to find those records which have duplicates, then we need to find the count of such records. Like shown below -
select count(ename) from (
select ename from emp group by ename having count(ename) > 1)
For (c), when you want to delete the duplicate records then you need to decide 1) either you need to delete all the
duplicate leaving any one from those duplicate records 2) or decide which one duplicate record you want to retain.
Once it is decided then only you can design the correct query. Like in below query, I have considered that I will retain
the duplicate record with minimum RowId, while other duplicate records will be deleted -
delete from emp where (ename, rowid) not in (
select ename, min(rowid) from emp group by ename)
Question : One another interesting Question can be asked by the interviewer is -
a) Find the number of duplicate records.
OR
b) Find the number of records which have duplicates in the given table.
OR
c) Remove all the duplicate records such that all records are unique in the given table.
OR
d) Remove the duplicates of a particular record in the table.
Ans : If you see all these questions are the variations of the same kind of problem. So if you get the crux of the problem here,
you can solve all such problems in different ways including RANK(). Using RANK(), you have to check on internet, I am
giving other way here. I assure you 50% interviewers ask these questions after getting their answers from Internet.
For (a) First get the clarity about the criteria on the basis of which you will consider 2 records as same. Till you get this
clarity, you can't write a correct solution ever. Here I am considering the 'Employee Name' as deciding factor for all the
questions. So now we need to find the difference between total number of records in the given table & the count of
distinct records in that table like -
select count(*)-count(distinct ename) as "Number of duplicate records" from emp
For (b) we don't need to find the number of duplicate records, but we need to find the number of those records which
have duplicates, got the trick here? So first we need to find those records which have duplicates, then we need to find the count of such records. Like shown below -
select count(ename) from (
select ename from emp group by ename having count(ename) > 1)
For (c), when you want to delete the duplicate records then you need to decide 1) either you need to delete all the
duplicate leaving any one from those duplicate records 2) or decide which one duplicate record you want to retain.
Once it is decided then only you can design the correct query. Like in below query, I have considered that I will retain
the duplicate record with minimum RowId, while other duplicate records will be deleted -
delete from emp where (ename, rowid) not in (
select ename, min(rowid) from emp group by ename)
Below video tells about some good questions & don't confuse every answer with Oracle here, as it seems to be more SQLServer oriented.
Top 65 Oracle PL/SQL Interview Questions in 2022 (mindmajix.com)
Top 50 Oracle Interview Questions and Answers (2022 Update) (guru99.com)
Top 50 Oracle Interview Questions and Answers in 2022 | Edureka
Top 50 Oracle Interview Questions and Answers (2022 Update) (guru99.com)
Top 50 Oracle Interview Questions and Answers in 2022 | Edureka
