Oracle Tips...
Not able to start the database due to missing .dbf file
If database is not starting due to some .dbf file is missing or you deleted any such file by mistake.
If that .dbf file was not having any important data you want, then you can try below things else you need to look RMAN steps on internet to recover the lost file and that will only be possible if recovery is enable in your DB, but still better to look all the possible RMAN options over the Oracle Docs or internet.
So, if you deleted some .dbf file by mistake, then below scenarios -
A) If you are still connected to DB as sysdba and you can try to create the .dbf file while creating the tablespace.
B) If you are not connected as sysdba, then connect to your DB as sysdba. Due to missing .dbf file that particular database is having issue & not the whole DB(Oracle) is down then execute the below command -
SQL> SELECT dd.tablespace_name tablespace_name, dd.file_name file_name FROM sys.dba_data_files dd;
And check if your missing .dbf file is being shown here, if yes then execute below command -
SQL> alter database datafile '/opt/apps/oraclexe/demo/<dbf file name>.dbf' offline drop;
SQL> alter database open;
Database altered.
SQL> drop tablespace <Tablespace_Name> including contents cascade constraints;
Tablespace dropped.
If still your DB is not starting-up then follow the commands in the given order -
1. STARTUP NOMOUNT;
2. ALTER DATABASE MOUNT;
3. ALTER DATABASE DATAFILE '<.dbf file name including its path>' OFFLINE DROP;
4. ALTER DATABASE OPEN;
5. DROP TABLESPACE <tablespace using the missing .dbf file> INCLUDING CONTENTS;
Tip: In case you cannot drop the tablespace then you can try the command without the "INCLUDING CONTENTS" after dropping all the object in the tablespace. So first drop all the objects in the tablespace and second execute:
DROP TABLESPACE TEST;
===============================================================================================
Pagination in Oracle
While working in Oracle to get certain set of rows from the rows in the table, number of rows in the table need to considered
as the efficiency of your task.
If writing the query solves your requirement in hand then can consider below 2 queries -
a) Use this way if you are having many rows from which you are required to get your required set, as this doesn't require
intermediate view for you to create & ranks to the rows are pushed using Window and Filter predicates. So it costs less.
SELECT * FROM
( SELECT deptno, ename, sal, ROW_NUMBER() OVER (ORDER BY ename) Row_Num FROM emp)
WHERE Row_Num BETWEEN &start and &end;
But now let us add order by also to the inner query -
SELECT * FROM
( SELECT deptno, ename, sal, ROW_NUMBER() OVER (ORDER BY ename) Row_Num FROM emp order by Row_Num)
WHERE Row_Num BETWEEN &start and &end;
It will not reduce the cardinality but it reduces the cost a bit, so you can try this trick.
b) If the number of rows are less or you need not to execute the query frequently then one can try below query -
select * from (select deptno, ename, sal, rownum Row_Num from (select deptno, ename, sal from emp order by ename)) where Row_Num between &start and &end;
Here one extra subquery is required because rownum < 5 kind of filter doesn't work in where clause of the query.
And if you are planning to fetch all the rows but in batches, may be 100 records from the million number of records in the table.
So you definitely be running any one from above queries multiple times & it will definitely take a lot of time.
Here suggestion will be to have procedure or function & fetch all the rows or as many rows as per the memory available.
And then fetch the required number of rows from the fetched data. Continue these 2 steps in the pl/sql block till you have fetched all the rows from the table. This will avoid multiple calls to the DB.
For more information check - stackoverflow.com/questions/13738181/best-practice-for-pagination-in-oracle
viralpatel.net/blogs/oracle-pagination-using-rownum-limiting-result-set/
===============================================================================================
Lets see one normal problem good for interviews -
Ques - You need to provide the list of employees in every department but sort the names of those employees based on their
salary in decreasing order but if 2 employees have the same salary then sort their names in increasing order.
Solution : select deptno, ename, sal from emp group by deptno, ename, sal order by deptno,sal desc, ename asc;
If database is not starting due to some .dbf file is missing or you deleted any such file by mistake.
If that .dbf file was not having any important data you want, then you can try below things else you need to look RMAN steps on internet to recover the lost file and that will only be possible if recovery is enable in your DB, but still better to look all the possible RMAN options over the Oracle Docs or internet.
So, if you deleted some .dbf file by mistake, then below scenarios -
A) If you are still connected to DB as sysdba and you can try to create the .dbf file while creating the tablespace.
B) If you are not connected as sysdba, then connect to your DB as sysdba. Due to missing .dbf file that particular database is having issue & not the whole DB(Oracle) is down then execute the below command -
SQL> SELECT dd.tablespace_name tablespace_name, dd.file_name file_name FROM sys.dba_data_files dd;
And check if your missing .dbf file is being shown here, if yes then execute below command -
SQL> alter database datafile '/opt/apps/oraclexe/demo/<dbf file name>.dbf' offline drop;
SQL> alter database open;
Database altered.
SQL> drop tablespace <Tablespace_Name> including contents cascade constraints;
Tablespace dropped.
If still your DB is not starting-up then follow the commands in the given order -
1. STARTUP NOMOUNT;
2. ALTER DATABASE MOUNT;
3. ALTER DATABASE DATAFILE '<.dbf file name including its path>' OFFLINE DROP;
4. ALTER DATABASE OPEN;
5. DROP TABLESPACE <tablespace using the missing .dbf file> INCLUDING CONTENTS;
Tip: In case you cannot drop the tablespace then you can try the command without the "INCLUDING CONTENTS" after dropping all the object in the tablespace. So first drop all the objects in the tablespace and second execute:
DROP TABLESPACE TEST;
===============================================================================================
Pagination in Oracle
While working in Oracle to get certain set of rows from the rows in the table, number of rows in the table need to considered
as the efficiency of your task.
If writing the query solves your requirement in hand then can consider below 2 queries -
a) Use this way if you are having many rows from which you are required to get your required set, as this doesn't require
intermediate view for you to create & ranks to the rows are pushed using Window and Filter predicates. So it costs less.
SELECT * FROM
( SELECT deptno, ename, sal, ROW_NUMBER() OVER (ORDER BY ename) Row_Num FROM emp)
WHERE Row_Num BETWEEN &start and &end;
But now let us add order by also to the inner query -
SELECT * FROM
( SELECT deptno, ename, sal, ROW_NUMBER() OVER (ORDER BY ename) Row_Num FROM emp order by Row_Num)
WHERE Row_Num BETWEEN &start and &end;
It will not reduce the cardinality but it reduces the cost a bit, so you can try this trick.
b) If the number of rows are less or you need not to execute the query frequently then one can try below query -
select * from (select deptno, ename, sal, rownum Row_Num from (select deptno, ename, sal from emp order by ename)) where Row_Num between &start and &end;
Here one extra subquery is required because rownum < 5 kind of filter doesn't work in where clause of the query.
And if you are planning to fetch all the rows but in batches, may be 100 records from the million number of records in the table.
So you definitely be running any one from above queries multiple times & it will definitely take a lot of time.
Here suggestion will be to have procedure or function & fetch all the rows or as many rows as per the memory available.
And then fetch the required number of rows from the fetched data. Continue these 2 steps in the pl/sql block till you have fetched all the rows from the table. This will avoid multiple calls to the DB.
For more information check - stackoverflow.com/questions/13738181/best-practice-for-pagination-in-oracle
viralpatel.net/blogs/oracle-pagination-using-rownum-limiting-result-set/
===============================================================================================
Lets see one normal problem good for interviews -
Ques - You need to provide the list of employees in every department but sort the names of those employees based on their
salary in decreasing order but if 2 employees have the same salary then sort their names in increasing order.
Solution : select deptno, ename, sal from emp group by deptno, ename, sal order by deptno,sal desc, ename asc;
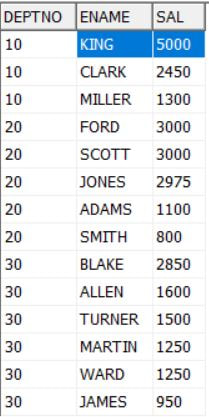
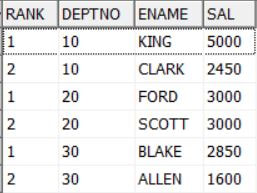
Another follow-up question - Give the top 2 high salaried from each department. So above we saw how to sort the employees
in each department, but to have ranking system we need more support. So we will use
Row_Number() function instead of Rank() or Dense_Rank(), Why? Simply don't make the things
tricky for this simple requirement.
select * from (
select Row_Number() over(partition by deptno order by sal desc) rank, deptno, ename, sal from emp group by deptno, ename, sal order by deptno,sal desc, ename asc)
where rank < 3;
in each department, but to have ranking system we need more support. So we will use
Row_Number() function instead of Rank() or Dense_Rank(), Why? Simply don't make the things
tricky for this simple requirement.
select * from (
select Row_Number() over(partition by deptno order by sal desc) rank, deptno, ename, sal from emp group by deptno, ename, sal order by deptno,sal desc, ename asc)
where rank < 3;
===============================================================================================
There are following type of statements :-
DDL : Create, Alter, Drop
DML : Insert, Update, Delete
DQL : Select
DCL/ACL : Grant, Revoke
TCL : Commit, Rollback, Savepoint
===============================================================================================
Have a look on various other SQL/Windows functions available in SQL, like Pivot() or explode(), Rank() etc...
There are following type of statements :-
DDL : Create, Alter, Drop
DML : Insert, Update, Delete
DQL : Select
DCL/ACL : Grant, Revoke
TCL : Commit, Rollback, Savepoint
===============================================================================================
Have a look on various other SQL/Windows functions available in SQL, like Pivot() or explode(), Rank() etc...
